P
Télécharger le PDF du cours
Soutenez-nous sur Patreon pour télécharger
Introduction
L’expression de l’information génétique est le passage de l’ADN (polynucléotide) aux caractères héréditaires observables et mesurables (le phénotype).
- Quelle est la relation entre l’information génétique (ADN) et les caractères héréditaires ?
- Quels sont les mécanismes de l’expression de l’information génétique ?
I – Notion de mutation et du gène
1 – Notion de mutation
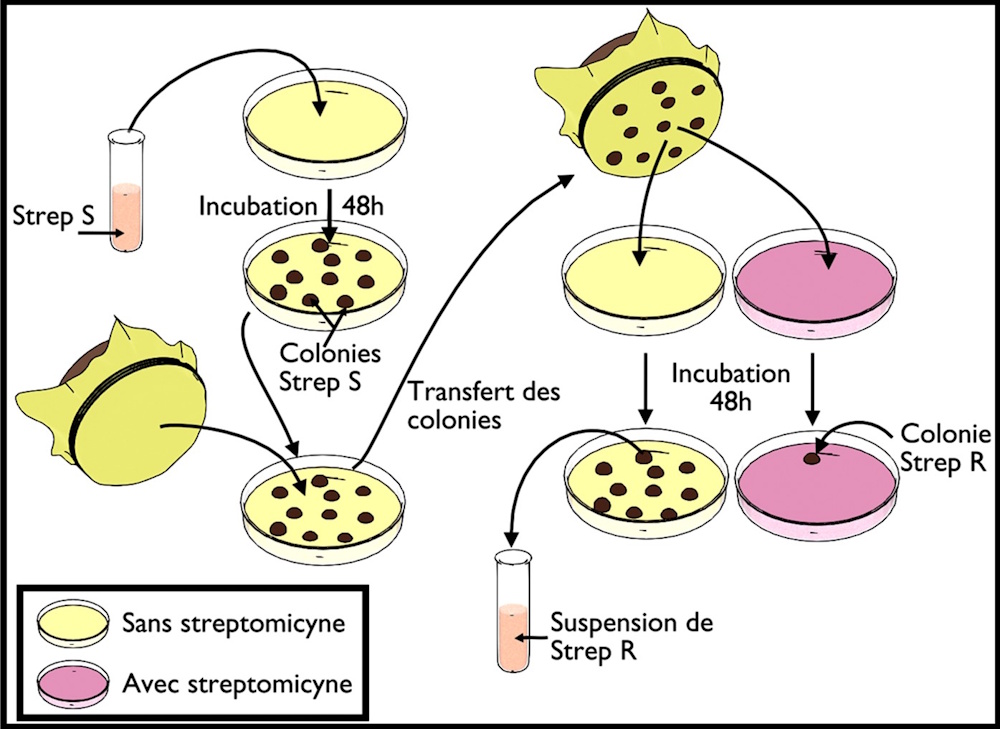
Des bactéries (E. coli) sensibles à la streptomycine sont cultivées sur une boîte de Pétri contenant un milieu nutritif adéquat. Après un certain temps, plusieurs colonies bactériennes apparaissent dans la boîte. Elles sont ensuite transférées sur un milieu nutritif contenant de la streptomycine. La figure suivante présente les résultats de cette expérience.
Q-1 – Nommez le caractère héréditaire considéré dans cet exemple et précisez ses phénotypes.
Q-2 – Décrivez les résultats de cette expérience.
Q-3 – Proposez une explication à ces résultats.
R-1 – le caractère héréditaire considéré est le comportement vis-à-vis de la streptomycine. Il se manifeste par 2 phénotypes :
- Strep S : sensible à la streptomycine.
- Strep R : résistant à la streptomycine.
R-2 – Le transfert des bactéries Strep S au milieu sans streptomycine conduit au développement de toutes les colonies initiales. Par contre, lorsque les mêmes bactéries sont transférées au milieu contenant de la streptomycine, on observe le développement d’une seule colonie qui est constituée de bactéries résistantes à la streptomycine.
R-3 – Les bactéries Strep R ont subi une modification du caractère héréditaire, cette modification est liée à une modification du programme génétique, cette modification est appelée mutation.
La mutation est une modification du matériel génétique (ADN) entraînant la modification d’un caractère héréditaire. Elle est spontanée (mais peut être provoquée par des agents mutagènes), aléatoire, rare et héréditaire.
Remarque : on distingue 3 types de mutations ponctuelles :
- Mutation par substitution : remplacement d’un nucléotide par un autre.
- Mutation par insertion : ajout d’un ou plusieurs nucléotides.
- Mutation par délétion : perte d’un ou plusieurs nucléotides.
2 – Notion du gène
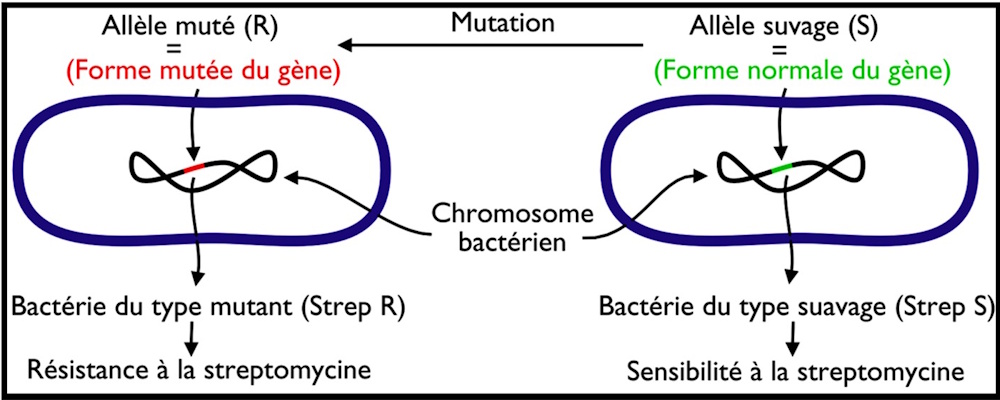
Le caractère de sensibilité ou résistance à la streptomycine est contrôlé par un morceau d’ADN appelé gène. Ce gène existe en deux formes appelées allèles : un allèle sauvage, chez les bactéries Strep S, qui gouverne la sensibilité à la streptomycine, et un allèle muté, chez les bactéries Strep R, responsable de la résistance à la streptomycine. La figure suivante montre un schéma simplifié qui illustre la notion du gène et des allèles.
Q – À l’aide du schéma, proposez une définition du gène et de l’allèle.
R – Définitions :
Gène : portion d’ADN qui porte l’information génétique correspondant à un caractère héréditaire. Le gène a une position (locus) constante sur un chromosome chez tous les individus de même espèce.
Allèle : forme ou version de gène. En général, un gène est représenté par deux allèles chez les diploïdes (occupant le même locus) qui peuvent être identiques ou différents.
II – Relation gène – protéine – caractère
1 – Relation protéine – caractère
Pour révéler la relation protéine – caractère, on propose l’étude de la maladie de l’anémie falciforme (drépanocytose).
C’est une maladie génétique qui se manifeste par une anémie (dont les principaux symptômes sont la fatigabilité, le vertige et l’essoufflement) et des crises douloureuses causées par une mauvaise circulation sanguine et par le manque d’oxygénation des tissus.
La figure suivante montre deux schémas de globules rouges.
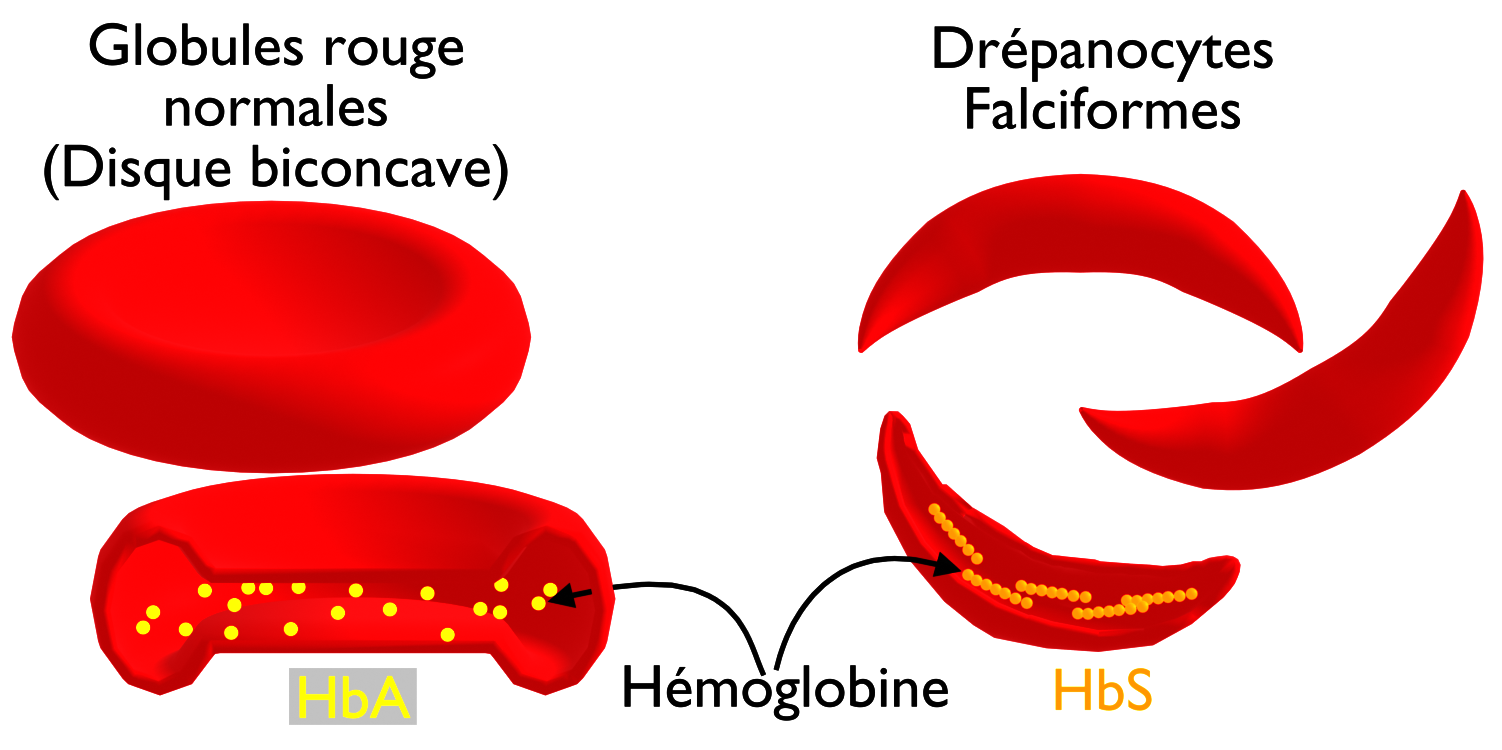
Q-1 – Comparez entre les globules rouges normales et les globules rouges anormaux.
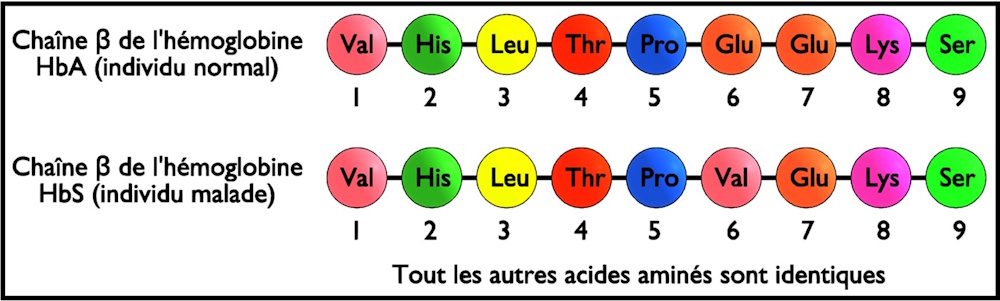
La figure suivante présente les premiers acides aminés des séquences de la chaîne Bêta de l’hémoglobine d’un individu normal (HbA) et d’un individu atteint de drépanocytose (HbS).
Q-2 – Comparez les séquences peptidiques et déduisez la relation protéine-caractère.
R-1 – On remarque que :
- Les hématies normales ont une forme normale disque biconcave, alors que les hématies anormales ont une forme de faucille.
- Les molécules d’hémoglobines des hématies normales (HbA) sont dissoutes et bien répartie dans le cytoplasme, alors que les molécules d’hémoglobines des hématies anormales (HbS) se rassemblent formant des fibres microscopiques. L’accumulation de ces fibres à l’intérieur des globules rouges provoque leur déformation.
R-2 – On constate un changement d’un acide aminé : au niveau de l’hémoglobine HbA l’acide aminé (6) est l’acide glutamique alors qu’au niveau de l’hémoglobine HbS l’acide aminé (6) est la valine (tous les autres acides aminés sont identiques).
On déduit que la modification de la séquence en acides aminés de la protéine entraîne une modification du caractère. Donc, il existe une relation protéine – caractère.
2 – Relation gène – protéine
La figure suivante présente les premiers acides aminés des séquences de la chaîne Bêta de l’hémoglobine et le début des séquences d’ADN du gène de la B-hémoglobine chez un individu sain et chez un individu drépanocytaire.
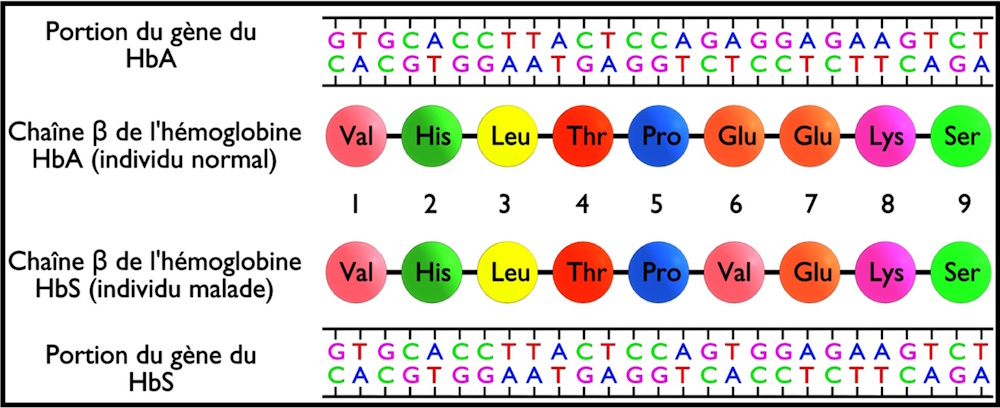
Q – Comparez les séquences d’ADN chez ces deux individus et déduisez la relation gène-protéine.
R – La différence réside dans un changement d’un nucléotide (mutation par substitution) au niveau de la paire de base N 17 ; en effet, la paire de nucléotide (A-T) est remplacée par (T-A).
Donc une mutation au niveau de la séquence nucléotidique entraîne une modification de la séquence en acides aminés de la protéine, ce qui montre l’existence d’une relation gène-protéine.
Bilan : Les mutations au niveau des séquences nucléotidiques entraînent une modification de la séquence en acides aminés de la protéine, ce qui provoque une modification du caractère héréditaire.
Il existe donc une relation gène – protéine – caractère héréditaire.
III – Mécanisme d’expression de l’information génétique
1 – L’intermédiaire entre le noyau et le cytoplasme
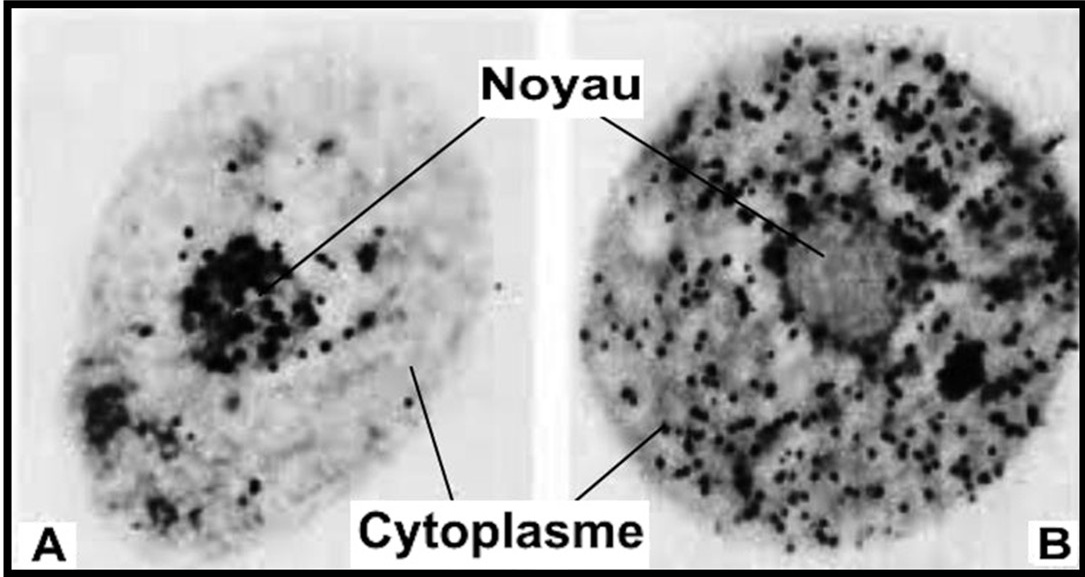
La figure suivante montre l’autoradiographie de deux cellules cultivées en présence d’un précurseur spécifique de l’ARN.
Q – Quel est le rôle de l’ARN que montre cette expérience ?
R – cette expérience montre que l’ARN est synthétisé dans le noyau (lieu de l’information génétique), puis il est transféré vers le cytoplasme (lieu de synthèse des protéines).
D’autres études ont montré qu’au niveau du cytoplasme, l’ARN intervient dans la synthèse des protéines.
2 – Comparaison entre l’ARN et ADN
l’ARN est l’acide ribonucléique, le tableau suivant montre une comparaison entre l’ARN et l’ADN.
| ADN | ARN |
Structure | Double brins | Un seul brin |
Sucre | Désoxyribose | Ribose |
Bases azotées | G, C, A, T | G, C, A, U (uracile) |
Localisation | Noyau (cytoplasme : mitose seulement) | Noyau et cytoplasme |
3 – Le code génétique
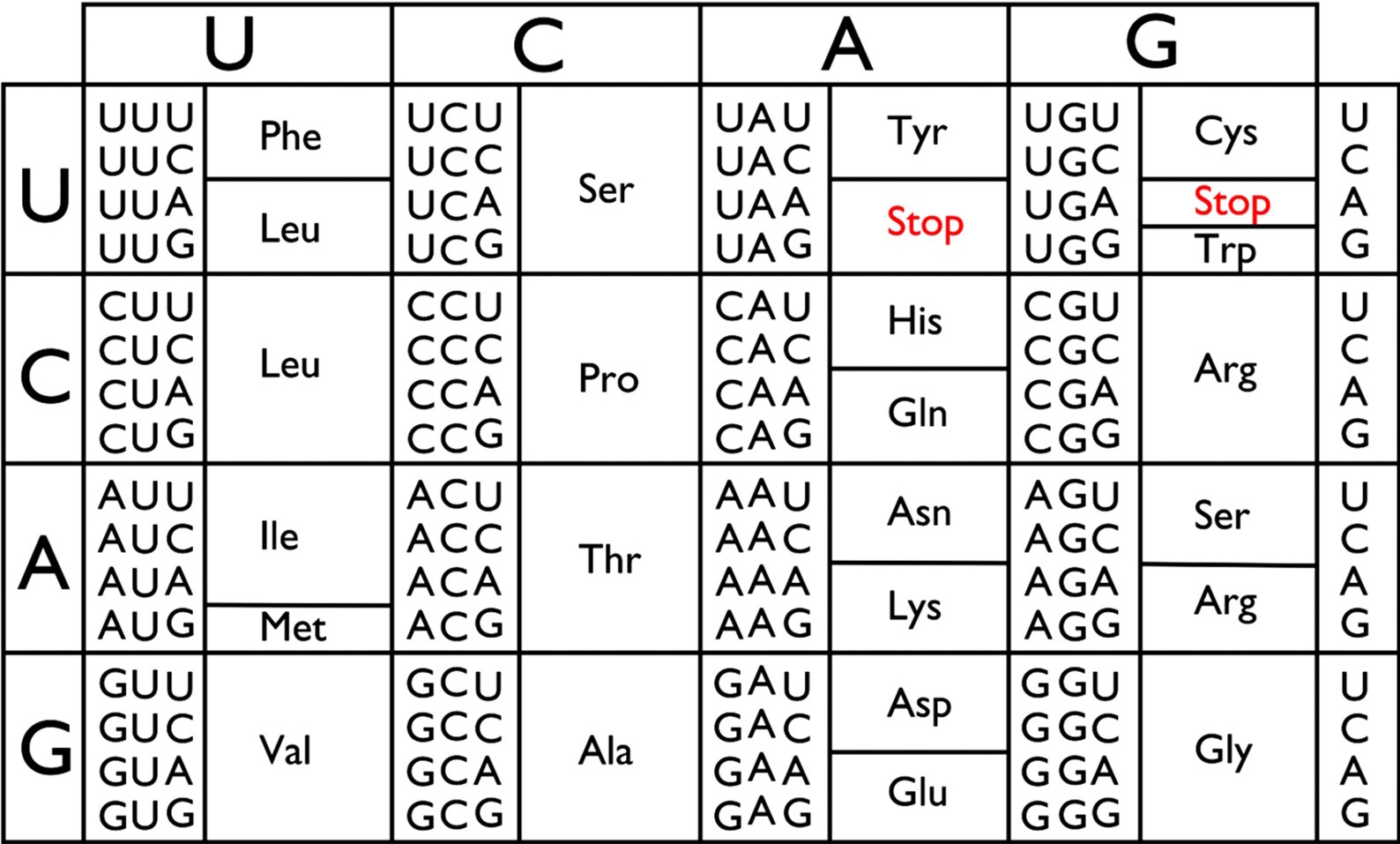
Après la transcription, le message du gène est contenu dans l’ARNm qui passe dans le cytoplasme, lieu de la synthèse des protéines. Cependant, l’ARNm est une séquence de 4 nucléotides, alors que chaque protéine est un enchaînement d’acides aminés dont on dénombre 20 acides aminés différents. Il est possible de désigner chaque acide aminé par un seul nucléotide (4 possibilités) ou même par une association de deux nucléotides (16 possibilités) mais cela reste insuffisant pour coder l’ensemble des 20 acides aminés.
En revanche, on peut constituer 64 associations différentes formées de (3) nucléotides. Des expériences ont permis de vérifier que c’est ce système de codage qui est utilisé par les cellules vivantes. Et d’autres travaux ont permis d’établir la correspondance entre les 64 triplets possibles de nucléotides (codons) et les 20 acides aminés existants, c’est le code génétique.
- L’universalité : la signification des codons est la même chez tous les êtres vivants.
- Il contient 3 codons stop.
- Le code est redondant, plusieurs codons peuvent correspondre au même acide aminé.
4 – Étape de l’expression de l’information génétique
a – Synthèse de l’ARN : Transcription
La figure suivante résume le mécanisme de la transcription.
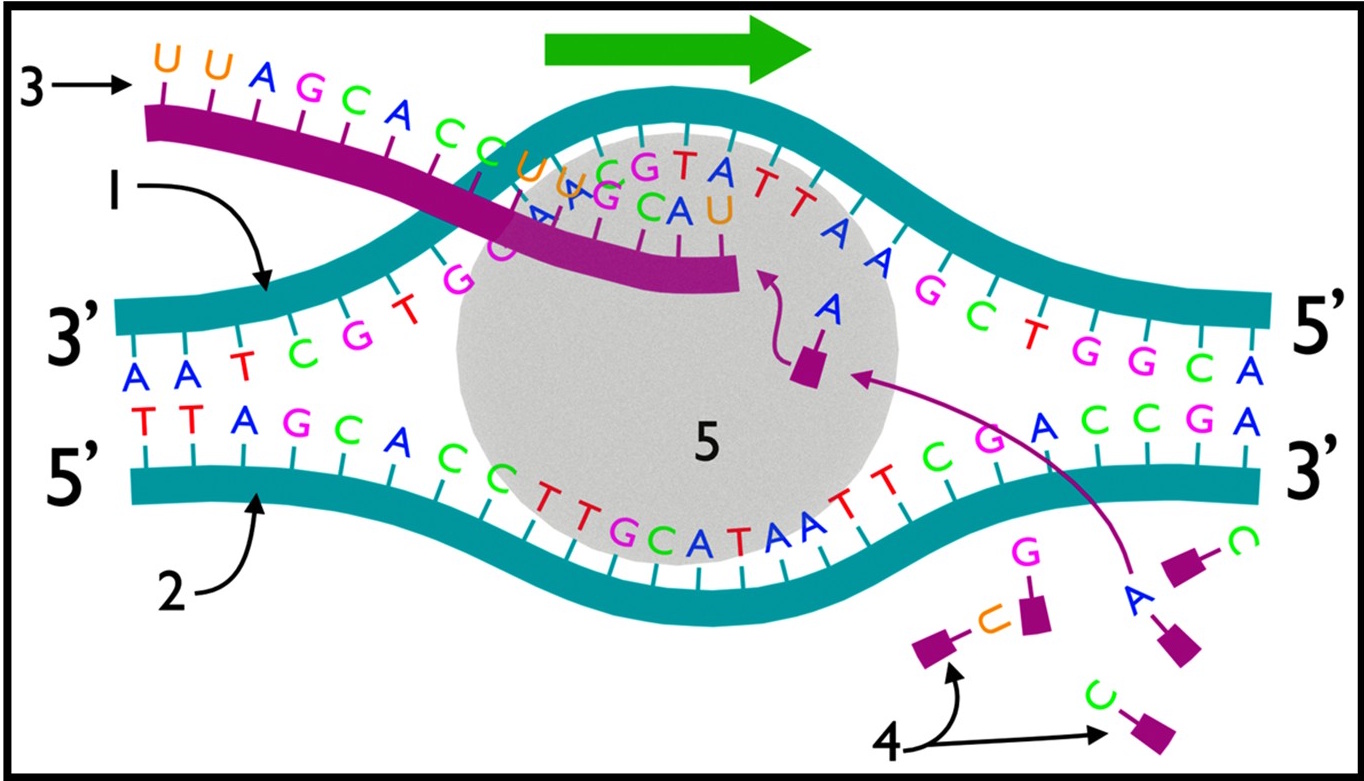
Q – décrivez le mécanisme de la transcription d’ARNm.
R – La transcription débute par le déroulement et l’ouverture d’une portion de la double hélice d’ADN (qui correspond à un gène). L’opération de transcription est catalysée par l’ARN polymérase. Au fur et à mesure de sa progression le long de l’ADN, cette enzyme incorpore des nucléotides par complémentarité avec l’un des brins de l’ADN. Le brin d’ARNm ainsi produit est complémentaire du brin d’ADN qui a servi de matrice, appelé brin transcrit (3’ → 5’).
Après la transcription, l’ARNm migre vers le cytoplasme à travers les pores nucléaires.
b – La traduction
La traduction est la synthèse des protéines dans le cytoplasme.
La traduction nécessite :
L’énergie.
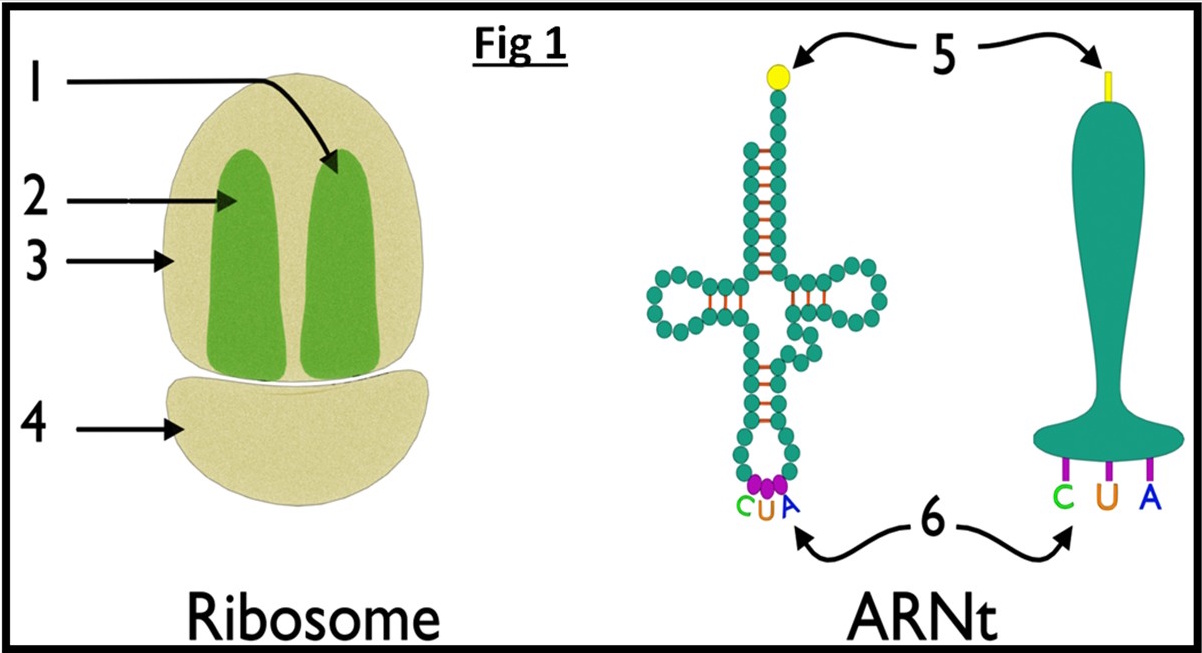
Les ribosomes : Organites responsables de la lecture des codons de l’ARNm et d’assemblage des acides aminés (fig).
L’ARNt : Se lit aux acides aminés et les transporte vers les ribosomes (fig).
La figure suivante montre des schémas explicatifs des étapes de la traduction.
Q – Décrivez les étapes de la traduction.
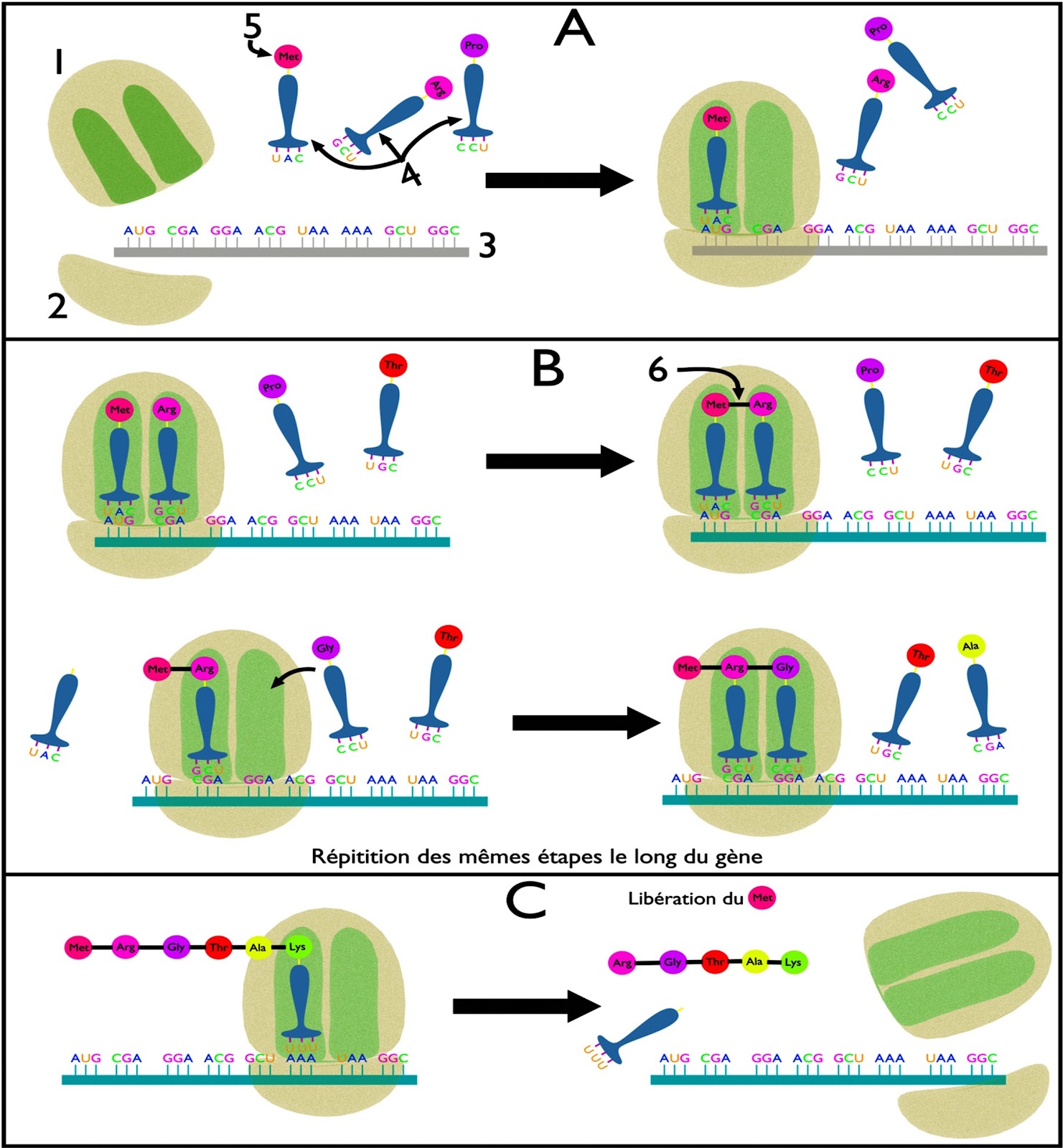
R – La traduction se fait selon 3 étapes :
- L’initiation : Le premier codon d’un gène est toujours AUG, l’ARNt initiateur, relié à la Méthionine, se fixe sur ce codon de l’ARNm, et le ribosome devient fonctionnel.
- L’élongation : Un nouvel ARNt se fixe en face du 2ᵉ codon de l’ARNm et une liaison peptidique se forme entre les deux acides aminés successifs. L’ARNt occupant le site (P) est libéré et le ribosome se déplace d’un codon (Translocation) pour permettre la mise en place d’un nouvel acide aminé et ainsi de suite.
- La terminaison : Le ribosome arrive à un codon stop (non sens) auquel ne correspond aucun acide aminé, donc aucun ARNt. Les deux sous-unités du ribosome se séparent et la chaîne protéique est libérée, la méthionine initiale est détachée.